Ceriumによる
正規表現マッチャの実装
Masataka Kohagura
14th May , 2013
Masataka Kohagura
14th May , 2013
本研究室では、Cell用に作られたCeriumにて並列プログラミングを行なっている。様々な例題を実装することにより、どのような問題でも並列処理ができることを証明する。
現在は文字列サーチを実装している段階で、ボイヤームーア法を実装している。 セミグループという、分割したファイルに対して並列処理をさせるような手法によって、既存の文字列サーチと処理速度を比較し、どれだけ速くなるのかを測定する。

検索したい文字列(pattern data)の長さをmとする。
pattarn dataとtext dataを、pattern dataの末尾から比較を行なっていく。
比較したtext dataの文字列がpattern dataの要素に含まれていない場合は、pattern dataをm個ずらし、再比較を行う。
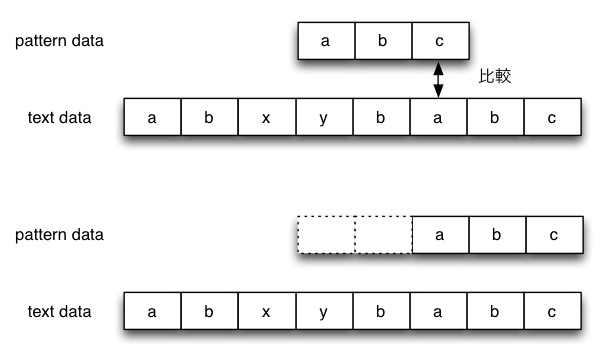
比較したtext dataの文字がpattern dataの要素に含まれている場合は、pattern dataの末尾からその要素がどれだけ離れているかで決定される。この図であれば、末尾から2個離れているので、pattern dataを2個ずらし、最比較。
int BM_method(char *text,char *pattern,unsigned long long *match_string){
int skip[256];
int i,j,text_len,pattern_len;
int k = 0;
text_len = strlen(text);
pattern_len = strlen(pattern);
for (i = 0; i < 256; ++i){
skip[i] = pattern_len;
}
for (i = 0; i < pattern_len-1 ; ++i){
skip[(int)pattern[i]] = pattern_len - i - 1;
}
i = pattern_len - 1;
while ( i < text_len){
j = pattern_len - 1;
while (text[i] == pattern[j]){
if (j == 0){
match_string[k] = text[i];
k++;
}
--i,--j;
}
i = i + max((int)skip[(int)text[i]],pattern_len - j);
}
return -1;
}
現在実装している処理
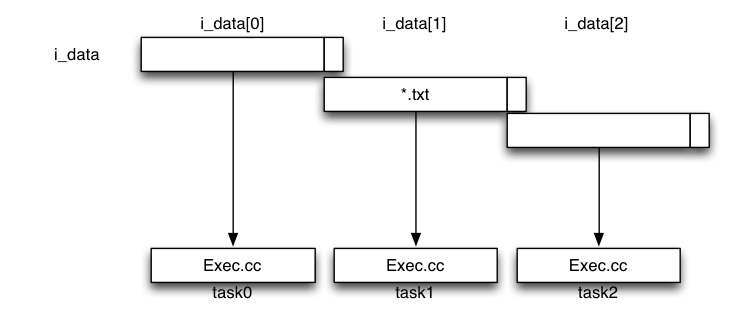
i_dataを1文字だけ多く取ってきて、abが分割されたときでも結果が返ってきてくれるように設定している。
分割回りで結果が返ってこない。(上手く処理されていない)
taskが2個以上になるとき、cpuの個数を2個以上に設定しないと結果が返ってこない。