Cell Broadband Engine
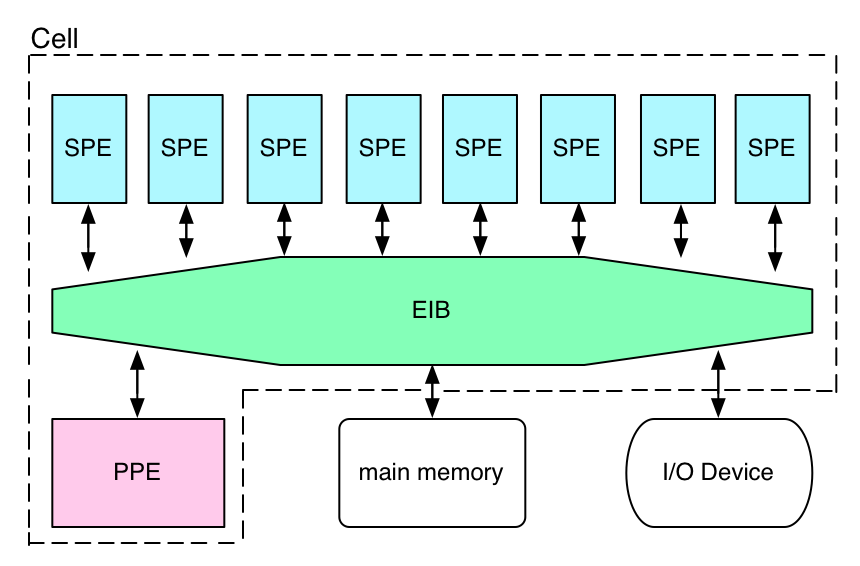
- 1 個の PPE と 8 個の SPE がリングバスで構成されている
- Linux 側から使える SPE は 6 個
- SPE は 256KB の Local Store (LS) を持つ
- SPE からメインメモリへ直接アクセスできない
- SPE が持つ MFC (Memory Flow Controller) へ DMA 命令を送ることで行う
- SPE は 128 ビットレジスタを 128 個持っている
Cell の基本機能
DMA (Direct Memory Access)
DMA とは CPU を介さずにデータ転送を行う機能。
- SPE は LS(256KB) にしかアクセスできない。
- メインメモリにアクセスするには、
MFC を通して DMA 転送命令を送る - LS にデータが転送されているあいだ、
SPE のプログラムは停止させたくない - SPE で処理したデータは MFC を介してメインメモリへ転送される
Cell の基本機能 (Con't)
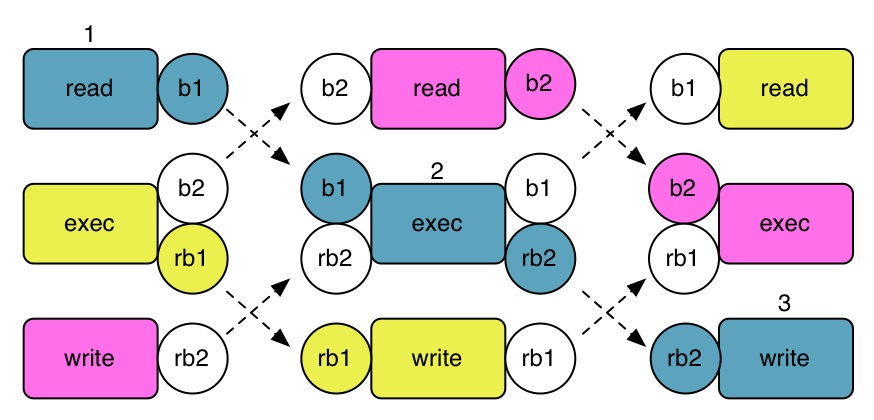
- DMA 転送には待ち時間が存在する。
- 待ち時間の間 SPE 有効に使わなければ、マルチコアプロセッサのパフォーマンスが極端に下がる。
- Task のデータを読み込む (1)
- 読み込んだデータの処理 (2) を行っている間に次の Task のデータを読み込む
- 処理したデータの転送 (3) の間に、2 で読み込んだデータの処理、次の Task のデータの読み込みを行う
Cerium
PS3 ゲーム開発用フレームワーク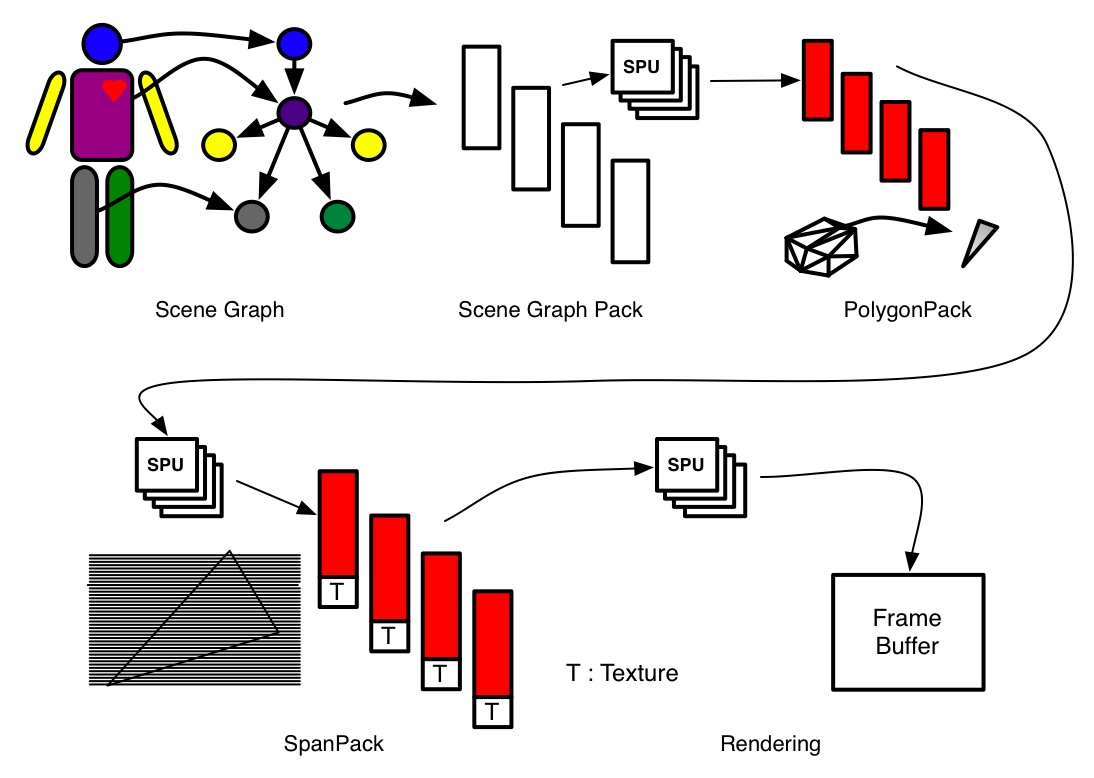
- Scene Graph
- ゲームに登場するオブジェクトやルールなど、ゲームを構成する要素をもつ木構造
- Rendering Engine
- Cerium 独自
- Task Manager
- Task と呼ばれる分割された各プログラムを管理するライブラリ
Scene Graph
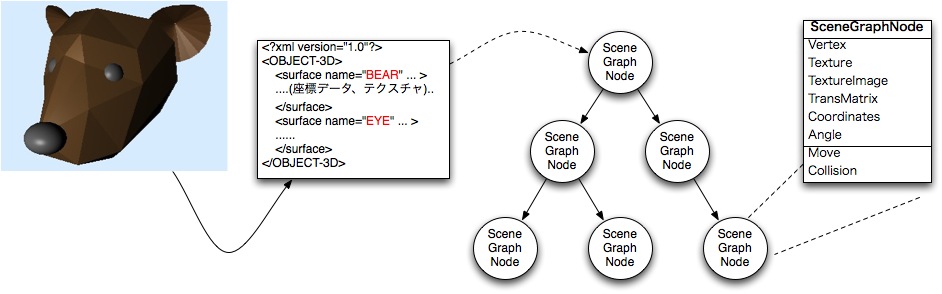
- Blender [1] で生成したオブジェクトを独自の XML 形式で出力
- XML が持つ情報 (頂点座標、テクスチャ座標、イメージ) などから SceneGraphNode を生成
- ポリゴン情報の他に、オブジェクトの操作 (move、
collision) を持つ
[1]オープンソースの3Dモデリングツール
Rendering Engine
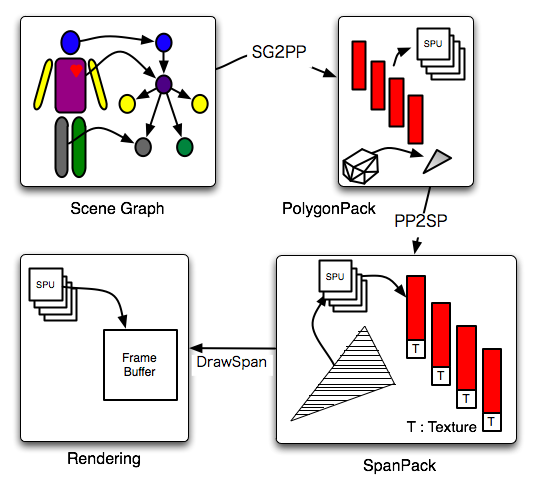 |
|
Rendering Engine (Con't)
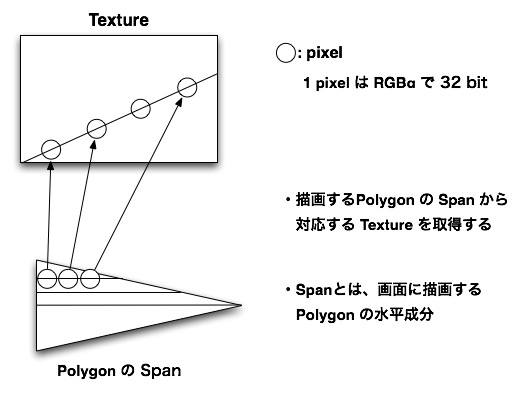
Rendering 部分の高速化
- SPE の LS は256KB しかないので、Texture 情報を一度に転送すると容量を超えてしまう可能性がある。
- そこで、描画に必要な Texture データを分割、転送するという手法を用いる。
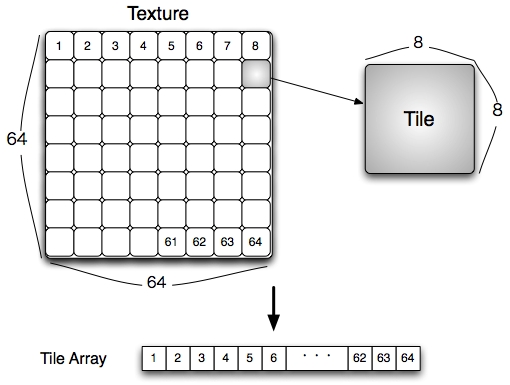
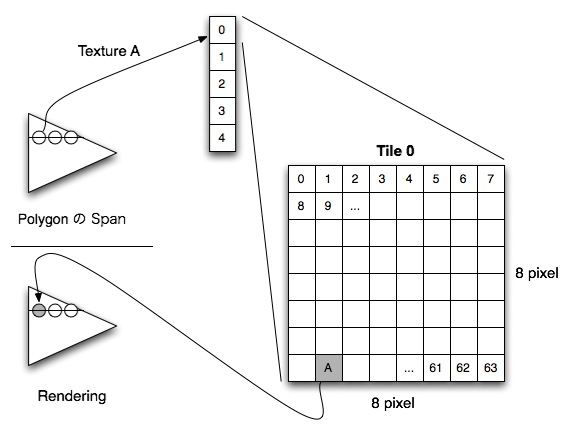
Rendering 部分の高速化 (Con't)
- Tile Array を用いた Rendering
- Polygon の Span から、描画に必要な Texture A を含む Tile を計算する
- Tile を SPE に転送し、Tile の中の pixel 情報 (RGBα値) を取得して描画を行う
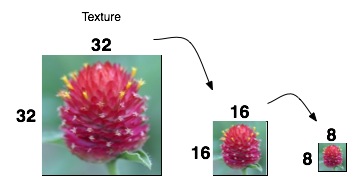
Scale
Texture の縮小画像の作成
描画されるオブジェクトが小さい場合、そのままの大きさの Texture は必要ない
Span の長さと、縮小 Texture の大きさが一致するような Scale の縮小 Texture を選択する
Texture は縦横ともに 1/2、1/4、1/8 と、2分の1ずつ縮小させる (最小 8x8 pixel)
Scale の効果検証
- 10個のオブジェクトを用いたサンプル
- Polygon 総数 は 19860
- Texture は合計 10 枚
( 8x8(3)、512x384(2)、616x123(4)、1024x768(1) )

比較 - Gallium (Con't)
- 実行速度比較
- 出力解像度は 1920x1080
- 地球のテクスチャを貼った球体のオブジェクトを表示
 |
ポリゴン数 : 1984
|
- Gallium には OpenGL API の機能が全て乗っているわけではない
- Cerium とのレンダリングの機能の違い
- 光源、アルファブレンディング、etc..