GNU コンパイラコレクション (GCC)
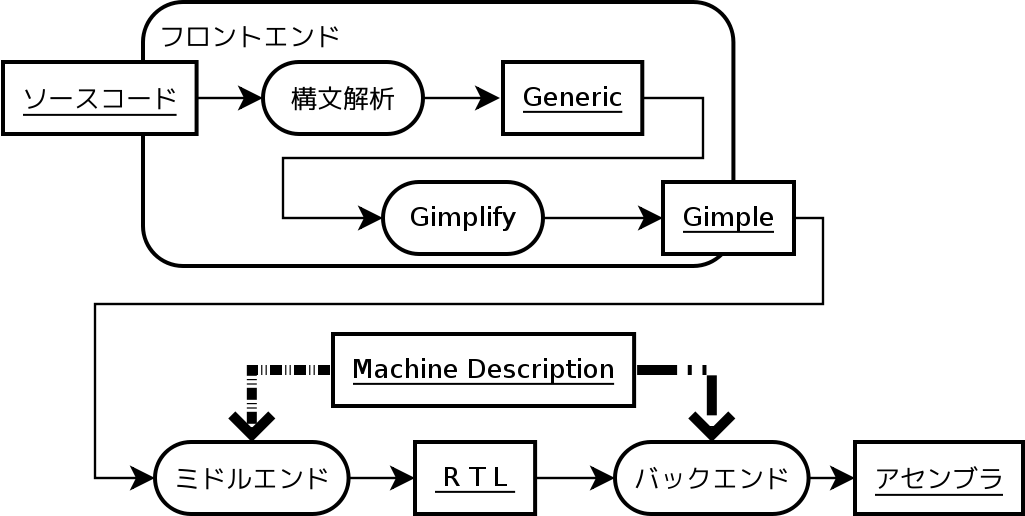
GCCでのコンパイルの流れ
- フロントエンド
- ミドルエンド
- バックエンド
与儀健人 (並列信頼研究室) <kent@cr.ie.u-ryukyu.ac.jp>
なにが問題になるのか?
状態遷移記述をベースとした、より細かい単位でのプログラミングを実現する
条件
継続を基本とする記述言語CbC
typedef code (*NEXT)(int);
int main(int argc, char **argv) {
int i;
i = atoi(argv[1]);
goto factor(i, print_fact);
}
code factor(int x, NEXT next) {
goto factor0(1, x, next);
}
code factor0(int prod,int x,NEXT next) {
if (x >= 1) {
goto factor0(prod*x, x-1, next);
} else {
goto (*next)(prod);
}
}
code print_fact(int value) {
printf("factorial = %d\n", value);
exit(0);
}
実際のプログラム記述は?
codeキーワードで宣言gotoキーワードと引数取り組み
GCCでのコンパイルの流れ
GCCでのコンパイルの流れ

軽量継続を実装するには?
末尾呼出をGCCに強制させる必要がある
末尾呼出ってなに?
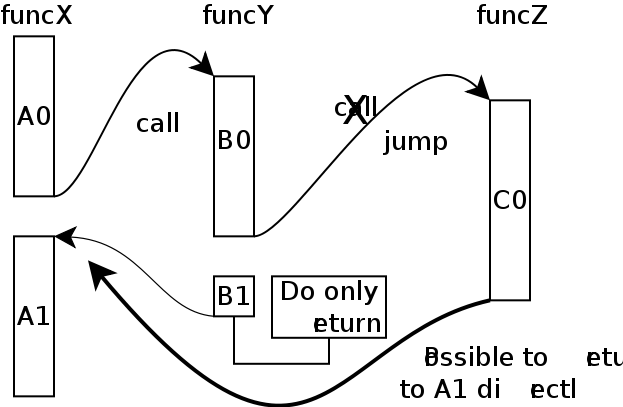
末尾呼出ってなに?
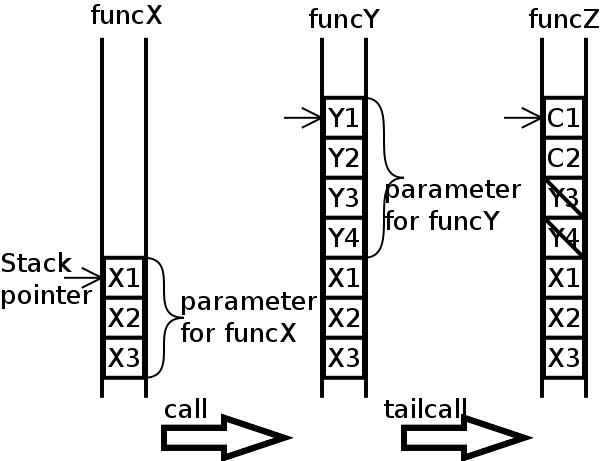
この末尾呼出(TCE)を強制して軽量継続を実装!
軽量継続は実装されたが、やはりmicro-cに比べると遅い
fastcallの導入
fastcallの強制
__code current(int a, int b, int c) __attribute__((fastcall));
これで軽量継続制御が高速化される!
CbCGCCとmicro-cで性能の比較
実行環境
速度測定結果(単位:秒)
| 新CbCGCC | 旧CbCGCC | |||
|---|---|---|---|---|
| 最適化無し | 最適化有り | 最適化無し | 最適化有り | |
| x86/OS X | 5.907 | 2.434 | 4.668 | 3.048 |
| x86/Linux | 5.715 | 2.401 | 4.525 | 2.851 |
評価
速度測定結果(単位:秒)
| 最適化なしのGCC | 最適化付きのGCC | micro-c | |
| x86/OS X | 5.901 | 2.434 | 2.857 |
| x86/Linux | 5.732 | 2.401 | 2.254 |
| ppc/OS X | 14.875 | 2.146 | 4.811 |
| ppc/Linux | 19.793 | 3.955 | 6.454 |
| ppc/PS3 | 39.176 | 5.874 | 11.121 |
結果(micro-cとの比較)
この違いはどこから?
なぜそれが必要か
環境付き継続の導入
typedef code (*NEXT)(int);
int main(int argc, char **argv) {
int i,a;
i = atoi(argv[1]);
a = factor(i);
printf("%d! = %d\n", a);
}
int factor(int x) {
NEXT ret = __return;
goto factor0(1, x, ret);
}
code
factor0(int prod,int x,NEXT next) {
if (x >= 1) {
goto factor0(prod*x, x-1, next);
} else {
goto (*next)(prod);
}
}
環境付き継続の使用例
__retunrで表される特殊なコードセグメント__returnに継続すると、元の関数の環境にリターン内部関数を用いた実装
__returnが参照された場合にGCCが自動で内部関数を定義するint factor(int x) {
int retval;
code __return(int val) {
retval = val;
goto label;
}
if (0) {
label:
return retval;
}
NEXT ret = __return;
goto factor0(1, x, ret);
} この取り組みにより
本研究での取り組み
本研究での成果
CbC言語の今後
ありがとうございました
本当に最適化で余分なコードが消えるのか?
_test:
stwu r1,-64(r1)
mr r30,r1
stw r3,88(r30)
stw r4,92(r30)
stw r5,96(r30)
lwz r0,92(r30)
stw r0,32(r30)
lwz r0,96(r30)
addic r0,r0,1
stw r0,28(r30)
lwz r0,88(r30)
stw r0,24(r30)
lwz r3,32(r30)
lwz r4,28(r30)
lwz r5,24(r30)
addi r1,r30,64
lwz r30,-8(r1)
lwz r31,-4(r1)
b L_next$stub
_test:
mr r0,r3
mr r3,r4
mr r4,r5
mr r5,r0
b L_next$stub
継続
CbCでの軽量継続
typedef code (*NEXT)(int);
int main(int argc, char **argv) {
int i;
i = atoi(argv[1]);
goto factor(i, print_fact);
}
code factor(int x, NEXT next) {
goto factor0(1, x, next);
}
code factor0(int prod,int x,NEXT next) {
if (x >= 1) {
goto factor0(prod*x, x-1, next);
} else {
goto (*next)(prod);
}
}
code print_fact(int value) {
printf("factorial = %d\n", value);
exit(0);
}
実際のプログラム記述は?
codeキーワードで宣言gotoキーワードと引数quicksort例題をCと比較すると
実際の出力アセンブラ
fastcallにした場合
current:
subl $12, %esp
movl $30, 16(%esp)
movl $20, %edx
movl $10, %ecx
addl $12, %esp
jmp next
normalcallの場合
current:
pushl %ebp
movl %esp, %ebp
movl $30, 16(%ebp)
movl $20, 12(%ebp)
movl $10, 8(%ebp)
leave
jmp next
ファイルサイズの比較
結果
| CbCGCC 速度最適化 |
CbCGCC サイズ最適化 |
micro-c | |
|---|---|---|---|
| x86/OS X | 9176 | 9176 | 9172 |
| x86/Linux | 5752 | 5752 | 5796 |
| ppc/OS X | 8576 | 8576 | 12664 |
| ppc/Linux | 10068 | 10068 | 9876 |
| ppc/PS3 | 6960 | 6728 | 8636 |
結果考察
ある条件で末尾呼出が行われなくなる
問題となる例
code somesegment(int a, int b, int c) {
/∗ do something ∗/
goto nextsegment(b, c, a);
}
(a,b,c) = (b,c,a)と本質的に同じ。これが並列代入a=b,b=c,c=aではだめ。aの値が失われる次の様に構文木を変更する
code somesegment(int a, int b, int c) {
int a1, b1, c1;
/∗ do something ∗/
a1=a; b1=b; c1=c;
goto nextsegment(b1, c1, a1);
}