ゲームフレームワーク Cerium TaskManager の改良
金城 裕, 河野 真治,
多賀野 海人, 小林 佑亮
琉球大学大学院理工学研究科情報工学専攻並列信頼研
概要
ゲームフレームワーク Cerium TaskManager を開発しました。- 動作環境:MacOSX, Linux, PS3/Cell
- 主にCellに特化している。
- SceneGraphを用いて、ゲームを記述する
琉球大学の学生実験で使用している。
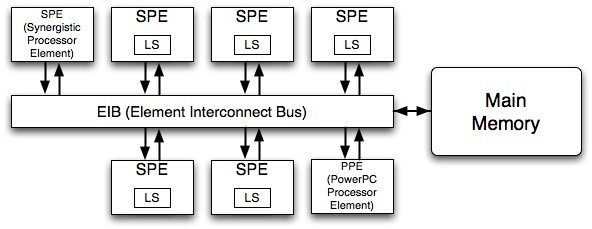
Cell
Cell Broadband Engine- ソニー・コンピュータエンタテインメント、ソニー、IBM , 東芝によって開発されたマルチコア CPU である
- 1基の制御系プロセッサコアPPE(PowerPC Processor Element)
- 8基の演算系プロセッサコアSPE(Synergistic Processor Element)
- 各コアはEIB(Element Interconnect Bus)とうバスで接続されている
Cell
Cell Broadband Engine
 |
DMA転送を用いてメインメモリからのデータを明示的に取得する
Cell
Cell のプログラミングスタイル- PPEがデータと仕事を分割し、各SPEへ割り当てる
Ceriumでは関数をTaskとして定義。Taskを各SPEへ割り当てる。
一つのTaskにはinput,output,param,等のデータを持たせる
Ceriumの構成
Ceriumの構成- TaskManager
- ユーザが定義したTaskを管理し、各コアに割り当てる
- RenderingEngine
- オブジェクトを画面に描画する
- 3種類のTaskから構成される
- SceneGraph
- ゲームのルールを記述してく
- ゲームのシーンを作成し、それを切り替えながらゲームを進行する
- OpenSceneGraphのようなもの
Ceriumの構成
 |
TaskManager
TaskManager- Taskは関数単位
- 定義されたTaskは依存関係に沿って実行される
- Taskはある程度の数が揃った上で、TaskListにまとめられSPEに送られる。
- Taskはread,exec,write それぞれパイプライン化されて動く
- Taskに必要なデータはDMA転送で送られる。転送時間はパイプライン化によって隠される
- Taskの中にDMA転送命令を書くと自動ではパイプライン化されない
TaskMangerを使った例題
CeriumのTaskManager を使ったSortの例題10万個のランダムな値をクイックソートでソートする
ソートする関数をTaskにして各SPEで実行
| PPEのみ | SPE 1つ | SPE 6つ | SPE稼働率 | |
|---|---|---|---|---|
| QuickSort | 5.60s | 6.22s | 1.07s | 97% |
アムダール則
プログラムの全体に対する並列化した部分の割合が低いと、マルチコアの性能がでない
 |
RenderingEngine
RenderingEngineの例題地球と月の例題
| FPS | mail待ちに割合 | SPE稼働率 | |
|---|---|---|---|
| universe | 17FPS | 72.6% | 25.4% |
RenderingEngine
SortとRenderingEngineの違い- 三種類のTaskから構成されている
- 三つのTaskはバリア同期を行っている
- すべてのTaskは一度に作られない
- PPEにもTaskが割り振られている
- 大量のデータを扱う(ポリゴン、テクスチャ)
RenderingEngine
RenderingEngienの場合の問題点- SPEの待ちが入る(SPEの稼働率の低下、処理性能の低下)
- MailをPPEが読み込みのを待つ
- 他のSPEを待つ
- 次のTaskListを待つ
- Taskはバリア同期している
バリア同期
 |
バリア同期
バリア同期には二つの待ちがある- SPEが他のSPEを待つ時間
- バリア同期が完了し、PPE側で次のTaskが作られる時間
バリア同期
 |
RenderingEngineの構成
RenderingEngineの構成- CreatePolygon
- モデリングデータからポリゴンを生成する(PPE)
- CreateSpan
- ポリゴンをSpanと呼ばれる水平な線に分ける(SPE)
- DrawSpan
- Spanを実際にディスプレイに描画する(SPE)
RenderingEngineは3種類のTaskから構成されている
パイプライン化
地球と月を表示する例題(universe)を使用。
 |
パイプライン化の比較
| FPS | mail待ちの割合 | 稼働率 | |
|---|---|---|---|
| Pipelineあり | 19.6FPS | 68.8% | 29% |
| Pipelineなし | 17FPS | 72.6% | 25.4% |
パイプライン化の比較
地球と月を表示する例題(universe)を使用。| FPS | mail待ちの割合 | 稼働率 | |
|---|---|---|---|
| Pipelineあり | 19.6FPS | 68.8% | 29% |
| Pipelineなし | 17FPS | 72.6% | 25.4% |
RenderingEngine
RenderingEngineでは、描画するためのテクスチャをSPEに読み込む必要があるテクスチャをSPE内でのキャッシュした。
- DrawSpan内で、描画するためのテクスチャデータを読み込む。
- テクスチャは分割さていて、必要な時に必要な部分を読み込む
- そこで、テクスチャをキャッシュするようにした(LRU)
- テクスチャのデータはハッシュで管理する
SPEのキャッシュ効果
| キャッシュなし | キャッシュあり | 性能 | |
|---|---|---|---|
| ball_bound | 4FPS | 30FPS | 7.5倍 |
| universe | 6FPS | 17FPS | 2.8倍 |
| panel | 0.2FPS | 2.6FPS | 13倍 |
SPEのキャッシュ効果
| キャッシュなし | キャッシュあり | 性能差 | |
|---|---|---|---|
| ball_bound | 28FPS | 30FPS | +2FPS |
| universe | 22.9FPS | 17FPS | -5.9FPS |
| panel | 5.0FPS | 2.6FPS | -2.4FPS |
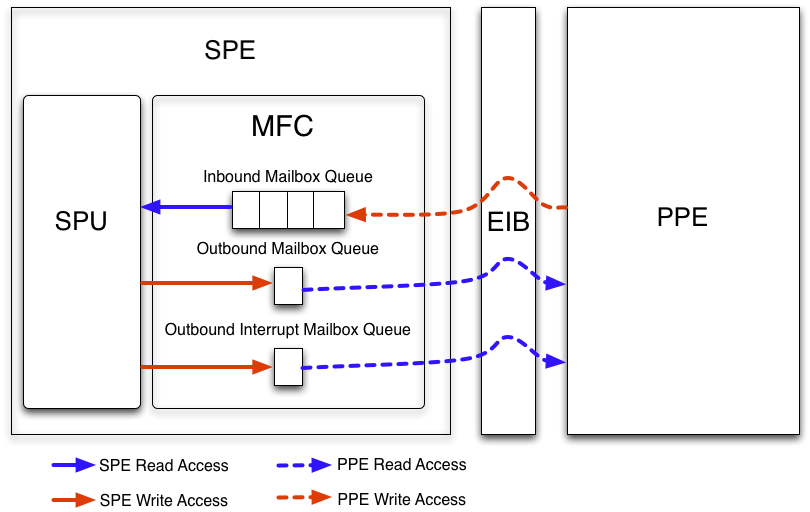
Mailbox機能
CellのMailbox機能- PPEとSPEとの間を双方向で32bitのデータを受け渡す
- FIFO キュー構造
Mailboxの種類
- Inbount Mailbox(PPE->SPE 4つ)
- Outbount Mailbox(SPE->PPE 一つ)
- Outbount interrupt Mailbox(SPE->PPE 一つ)
Mailbox機能
 |
Mailbox機能
SPE側からTaskが一つ実行完了する度に、実行完了のMailをOutboxに書きこむ- Outboxに既にMailが書きこまれている場合に、PPE側から読み込まれるまで、SPEは待つ(Cellの仕様)
- PPE側のMailチェックが追いつかない場合がある。
- その間、SPEは何もしないので、処理速度の低下につながる
そこで、Outboxに既に読み込まれていないMailがあった場合に、いったん、別のキューに追加する。(MailQueue)
MailQueue
- TaskListを消化し、次のTaskListを要求する時に、MailQueueにMailが残っている場合はそれを先に書きだす
- PPE側はMailのチェックをMailが無くなるまでループする
- PPEはMailがない場合に、自分の仕事に戻る。
- 今のPPEのMailチェックの仕様には、一度にMailを書きだすのが向いている
MailQueueの効果
| 改良前 | 改良後 | 性能 | |
|---|---|---|---|
| universe | 16FPS | 18.5FPS | 12%向上 |
TaskArray
Task毎のMailは、Task同士の依存関係を解決するために用いている。- 依存関係はグループ化できる
- TaskArrayを用いて複数のTaskのMailを一つに扱う
Mailの数を減らせるので、Mailのための処理が減る。その分処理速度が上がる
TaskArray
| 改良前 | 改良後 | 性能 | |
|---|---|---|---|
| universe | 16FPS | 18.5FPS | 12%向上 |
MailQueueとTaskArray
| TaskArray | MailQueue | FPS | 性能 |
|---|---|---|---|
| あり | あり | 20FPS | 22%向上 |
| あり | なし | 18.5FPS | 12%向上 |
| なし | あり | 18.5FPS | 12%向上 |
| なし | なし | 16.4FPS | 0%向上 |
OpenGLとの比較
OpenGL(Open Graphics Library)とは、Silicon Graphics社が開発した、3Dグラフィックス処理の ためのプログラミングインターフェース。Taskに分割され、SPEを使用したCeriumと、PPEのみで動作 するOpenGLとで、処理速度の比較をした。比較する例題には学生が実験中に作成したSuperDandyを用いた。
OpenGLとの比較
| OpenGL | Cerium | 性能差 | |
|---|---|---|---|
| dandy | 17.5FPS | 49.5FPS | 2.9倍 |
まとめ
本研究ではゲームフレームワーク Cerium TaskManager の改良を行った。 特にCell上において、SPEの稼働率に注意する必要があった。 SPE、PPE間のデータのやり取りにMail通知を用いている。SPEはMailの書き込みの際に待ちが発生する- MailQueue
- TaskArray
で待ち時間の削減ができる
まとめ
RenderingEngineにおいて、Taskがバリア同期をしている。バリア同期にも待ちが発生する- Task実行をパイプライン化
SPEの待ち時間を解消できる。頻繁に扱うデータはSPE内でキャッシュするのがよい
依存関係の話
稼働率を維持するためにパイプライン化がある- 扱うデータの依存性から、Pipelineを自動で生成できるはず
- TaskArrayもデータから自動でできるはず。
- データはSegmentとして扱う
Codeload
Taskを事前に全部ロードしてる- SPEのLSは256KB
- 大量のコードを入れるといっぱいになる
- 必要な時に必要な分を予測してSPEにロードするのがよい
Segment
データはすべてSegmentという形にして、SPEに必要な分を予測、読み込みするのがよい。テクスチャのように頻繁に扱うデータはキャッシュする
END
/*end*/
[any material that should appear in print but not on the slide]