Continuation based C
コードセグメント単位での記述と継続を基本としたプログラミング言語
- C の関数よりも細かな単位
- 構文は C と同じだが、C から関数コールとループ制御が取り除かれた形
- コードセグメントの末尾処理で別のコードセグメントへ継続(goto)することで CbC のプログラムは続いていく。

|
__code cs_a(int num) {
:
:
goto cs_b();
}
|
Presenter Notes
Continuation based C
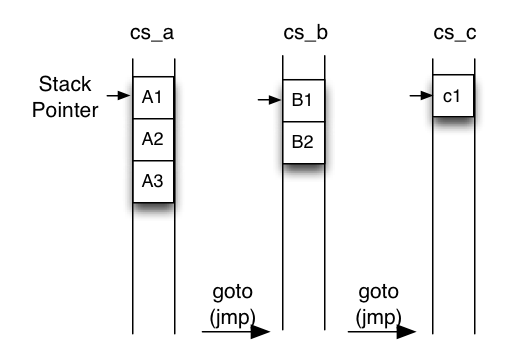
継続:現在の処理を実行していく為の情報
Cの継続 |
CbCの継続(軽量継続) |
|
|

|
|
Presenter Notes
Gnu Compiler Collection (GCC)

|
Presenter Notes
CbC の実装 : 軽量継続
Tail Call Elimination
void f(int a, int b) {
printf("f: a=%d b=%d\n",a,b);
return ;
}
void g(int a, int b){
printf("g: a=%d b=%d\n",a,b);
f(a,b);
return;
}
int main() {
g(3,4);
return 0;
}
|

|
Presenter Notes
GCC-4.5, GCC-4.6 の性能比較

|

|
| x86/Linux | x86/OS X (10.7) |
Presenter Notes
最適化の比較
| 最適化なし | GCC-4.5の最適化(-O2) | GCC-4.6の最適化(-O2) |

|
|

|
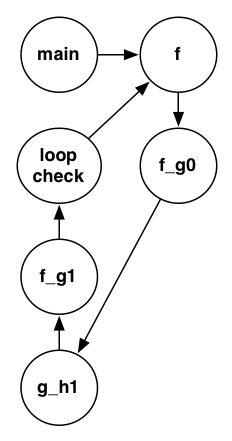
- 最適化無しに比べると GCC-4.5、 GGC-4.6 共にコードセグメントの数が減っている。
- GCC-4.5 でもインライン展開はされているが、GCC-4.6 はより良い最適化がかけられている。
Presenter Notes
jmp と call

|
Presenter Notes
CbC 引数渡し
| fastcall無し |

|
| fastcall有り |

|
Presenter Notes
引数の並びに上書きコピー
void funcA(int a, int b) {
funcB(b, a);
}

|
Presenter Notes
最適化の比較

|

|
| x86/Linux | x86/OS X (10.7) |