マルチプラットフォーム対応
並列プログラミングフレームワーク
|
Yuhi TOMARI
|
マルチプラットフォームなフレームワークにおける並列プログラミング 1/2
プログラムが PC に要求する処理性能は上がってきているが、
消費電力や発熱、クロックの限界といった問題から CPU の性能を上げることによる処理性能の向上は難しい。
プロセッサメーカーはマルチコア CPU や、GPU を含んだヘテロジニアス構成の路線を打ち出している。
クロックの性能を上げるのではなく、コア数を増やす事でパフォーマンスを向上させている。
マルチコア CPU や GPU といったマルチコアプラットフォームなアーキテクチャ上で
リソースを有効活用するには、それぞれのプラットフォームに最適な形でプログラムを並列に動作させる必要がある。
ここでいう最適な形とは、実行の順番やどのリソース上で Task を実行するかといった、
Scheduling を含めたチューニングのことである。
しかしこれらのチューニングは複雑で、コーディング時に毎回行うと複雑さや拡張性の問題がある。
マルチプラットフォームなフレームワークにおける並列プログラミング 2/2
そういった問題を解決するため、本研究では並列プログラミングフレームワーク、 Cerium の開発を行った。
異なるプラットフォーム上で最適なチューニングを行うため、以下の実装を行った。
- パイプライニングによる Task の並列実行
- OpenCL、CUDA を用いた GPGPU 対応
- データ並列実行
- 並列処理むけのI/O
Sort、WordCount、FFT といった例題を元に、これら Cerium の並列実行機構が
マルチプラットフォームにおける並列プログラミングで有効に作用することを示す。
並列プログラミングフレームワーク Cerium
Cerium は Linux、MacOSX 上で動作する汎用計算用の並列プログラミングフレームワークである。

Cerium を用いることでマルチコア CPU と GPU において Scheduling を含めたプログラミングを可能となる。
Cerium における Task の生成
Cerium TaskManager では処理の単位を Task としてプログラムを記述していく。
関数やサブルーチンを Task として扱い、Task に各種パラメタを設定した後に並列実行される。
Input データの各要素同士を乗算し、 Output に格納する Multiply という例題がある。
Multiply の例題を元に Cerium で Task が生成される様子を以下に示す。
void
multiply_init(TaskManager *manager, float *i_data1,
float *i_data2, float *o_data) {
// create task
HTask* multiply = manager->create_task(MULTIPLY_TASK);
multiply->set_cpu(spe_cpu);
// set indata
multiply->set_inData(0, i_data1, sizeof(float) * length);
multiply->set_inData(1, i_data2, sizeof(float) * length);
// set outdata
multiply->set_outData(0, o_data, sizeof(float) * length);
// set parameter
multiply−>set_param(0,(long)length);
// set device
multiply->set_cpu(SPE_ANY);
// spawn task
multiply−>spawn();
}
Cerium における Task の記述
Device 側で実行される Task の記述を示す。
static int
run(SchedTask ∗s) {
float ∗i_data1 = (float∗)s−>get_input(0); // get input
float ∗i_data2 = (float∗)s−>get_input(1); // get output
float ∗o_data = (float∗)s−>get_output(0); // get parameter
long length = (long)s−>get_param(0);
// calculate
for (int i=0; i<length; i++) {
o_data[i] = i_data1[i] ∗ i_data2[i];
}
return 0;
}
Host 側では Task を生成する際に様々なパラメタを設定しており、
Task にはそれを取得する API が用意されている。
| API | content |
| get_input | 入力データのアドレスを取得 |
| get_output | 出力先データのアドレスを取得 |
| get_param | パラメータを取得 |
TaskManager の構成
- TaskManagerと各Threadsの間には Syncronized な Mail Queueがある。
- 依存関係の解決された Task は TaskManager から Mail Queue に送られる。
- Task に設定された CPUType に対応した Threads が Mail Queue から Task を取得し、並列実行していく。
マルチコア CPU 上での並列実行
Cerium は Cell 上で動作するフレームワークであったが MacOSX、Linux 上での並列実行に対応させた。
マルチコア CPU 上での並列実行は、Synchronized Queue とパイプラインによって実現されている。
TaskManager で依存関係を解決された Task は Scheduler に送信され、
Scheduler が持っているパイプラインの機構に沿って並列に実行する。
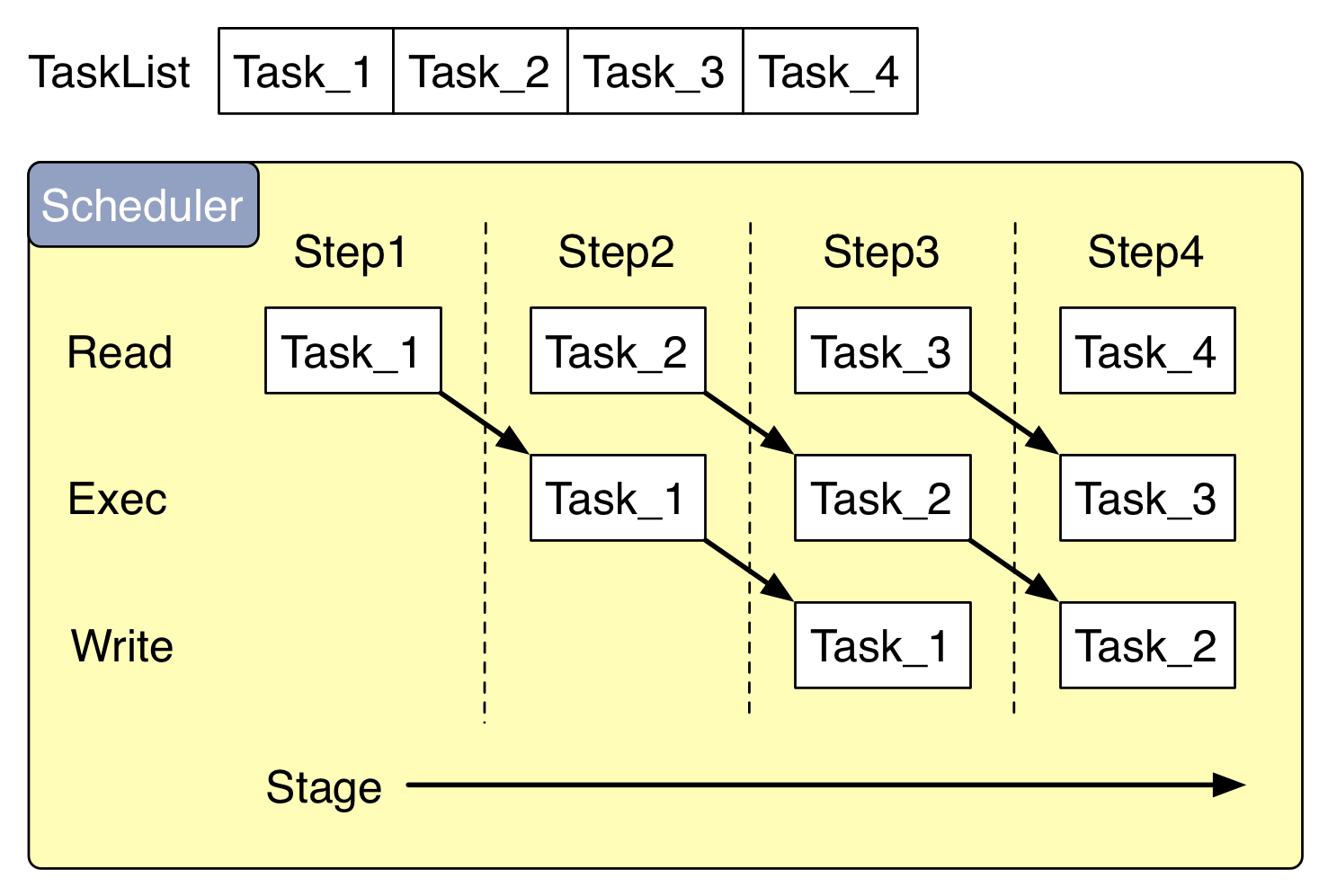
マルチコア CPU におけるパイプラインの実装
void
Scheduler::run(SchedTaskBase* task1) {
SchedTaskBase* task2 = new SchedNop();
SchedTaskBase* task3 = new SchedNop();
// main loop
do {
task1->read();
task2->exec();
task3->write();
delete task3;
task3 = task2;
task2 = task1;
task1 = task1->next(this, 0);
} while (task1);
delete task3;
delete task2;
}
|
Cerium の Task は SchedTask と呼ばれるデータ構造で表現されている。
SchedTask は read/exec/write のメソッドを持っており、
パイプラインの各ステージで段階的に実行される。
引数として TaskList を受け取り、List 内の Task をパイプライン実行する。
task3 が write を担当しており、write が終わった Task は終了となる。
終了した task は delete して良い。
task3=task2、task2=task1 と SchedTask をずらして行き、TaskList から 次の Task を読み込む。
|
DMA の prefetch を用いた改良
マルチコア CPU におけるデータ並列
GPU 上での並列実行
GPGPU におけるパイプラインの実装
GPGPU におけるデータ並列
Cerium の I/O(mmap による読み込み)
BlockedRead による I/O の並列化
I/O 専用のThread
実験に利用する例題-Sort-
実験に利用する例題-WordCount-
実験に利用する例題-FFT-
実験環境
マルチコア CPU による並列実行のベンチマーク
DMA の prefecth に関するベンチマーク
GPGPU のベンチマーク
データ並列実行のベンチマーク
GPGPU のベンチマーク
FFT による GPGPU のベンチマーク
BlockedRead による並列 I/O のベンチマーク
まとめ
今後の課題