|
Gears OS のモジュール化と並列 API
|
|
Mitsuki Miyagi, Yu Tobaru, Shinji Kono
琉球大学
|
Gears OS
- 現代のOS では拡張性と信頼性を両立させることが要求されている。
- 時代と共にハードウェア、サービスが進歩していき、その度に OS を検証できる必要があるため、拡張性が必要。
- OS は非決定的な実行を持ち、従来の OS ではテストしきれない部分が残ってしまうため、信頼性が欠けてしまうので信頼性のある OS が必要。
- 本研究室では、拡張性と信頼性を実現することを目標に Gears OS の開発を行なっている。
スライドの流れ
-
Interface
- 並列API
- CbC
- Gears OS における並列実行
- 比較
- 今後の課題
Gears OS での形式化とInterfaceの導入
- 形式化とは仕様、実装、実行を Logic で記述する事である。
- Gears OS では、継続を使った関数型プログラムとして実装を記述する
- Logic としては、依存型関数言語である Agda を使う(外間の発表)
- 証明とモデル検査を使って、信頼性を確保する
Gears OS の Interface
- Code Gear と Deta Gear は Interface と呼ばれるまとまり(モジュール)で記述される。
- Interface 作成時に Code Gear の集合を指定することにより複数の実装(並列処理)を持つことができる。
- Interface は Data Gear で記述されて、Meta Deta Gear と呼ばれる。
- Java などの Class に相当する。
- Data Gear に Interface を呼び出す時に必要となる引数を全て格納する
スライドの流れ
- Interface
-
並列API
- CbC
- Gears OS における並列実行
- 比較
- 今後の課題
並列API
- Geas OS 信頼性を保証(テスト)するために、モジュールシステムが必要である。
- 本研究では、モジュールシステムとその応用である並列APIについて考察する。
- 並列APIは継続を基本とした関数型プログラミングと両立する必要があり、ここでは CbC の goto 文を拡張した par goto を導入する。
- Interface でモジュール化
- 応用として par goto を使って 並列API を実装
スライドの流れ
- Interface
- 並列API
-
CbC
- Gears OS における並列実行
- 比較
- 今後の課題
CbC
- ノーマルレベルとメタレベルの計算をまとめて表現できる言語として、本研究室で設計した CbC を用いる。
- ノーマルレベルの計算
- コンピュータの計算はプログラミング言語で行われる。
- その部分をノーマルレベルの計算と呼ぶ。
- メタレベルの計算
- コードが実行される際の以下の部分が、メタレベルの計算という。
- 処理系の詳細や使用する資源
- コードの仕様や型などの部分
CbC
- CbC を用いることで、ノーマルレベルの計算の信頼性をメタレベルから保証できるようになる。
- 処理の詳細やコードの型を数え上げる事による信頼性の保証
- CbC を用いてCode Gear と Data Gear を導入する。
- Code Gear は並列処理の単位として利用
- Data Gear はデータそのもの
CbC の構文
- CbC の Code Gear は __code という型を持つ関数として記述する。
- 継続で次の Code Gear に遷移するので、戻り値は持たない。
- 遷移は goto 文による継続で処理を行い、引数として入出力を行う。
__code cg0(int a, int b) {
goto cg1(a+b);
}
__code cg1(int c) {
goto cg2(c);
}
スライドの流れ
- Interface
- 並列API
- CbC
-
Gears OS における並列実行
- 比較
- 今後の課題
Gears における並列実行
- Gears OS ではメタ計算を柔軟に記述するためのプログラミングの単位として Code Gear と Data Gear を用いる。
- それぞれにメタレベルの単位が存在し、Meta Data Gear と Meta Code Gear と呼ぶ。
- メタレベルの計算は Perl スクリプトによって生成され、Code Gear で記述される。
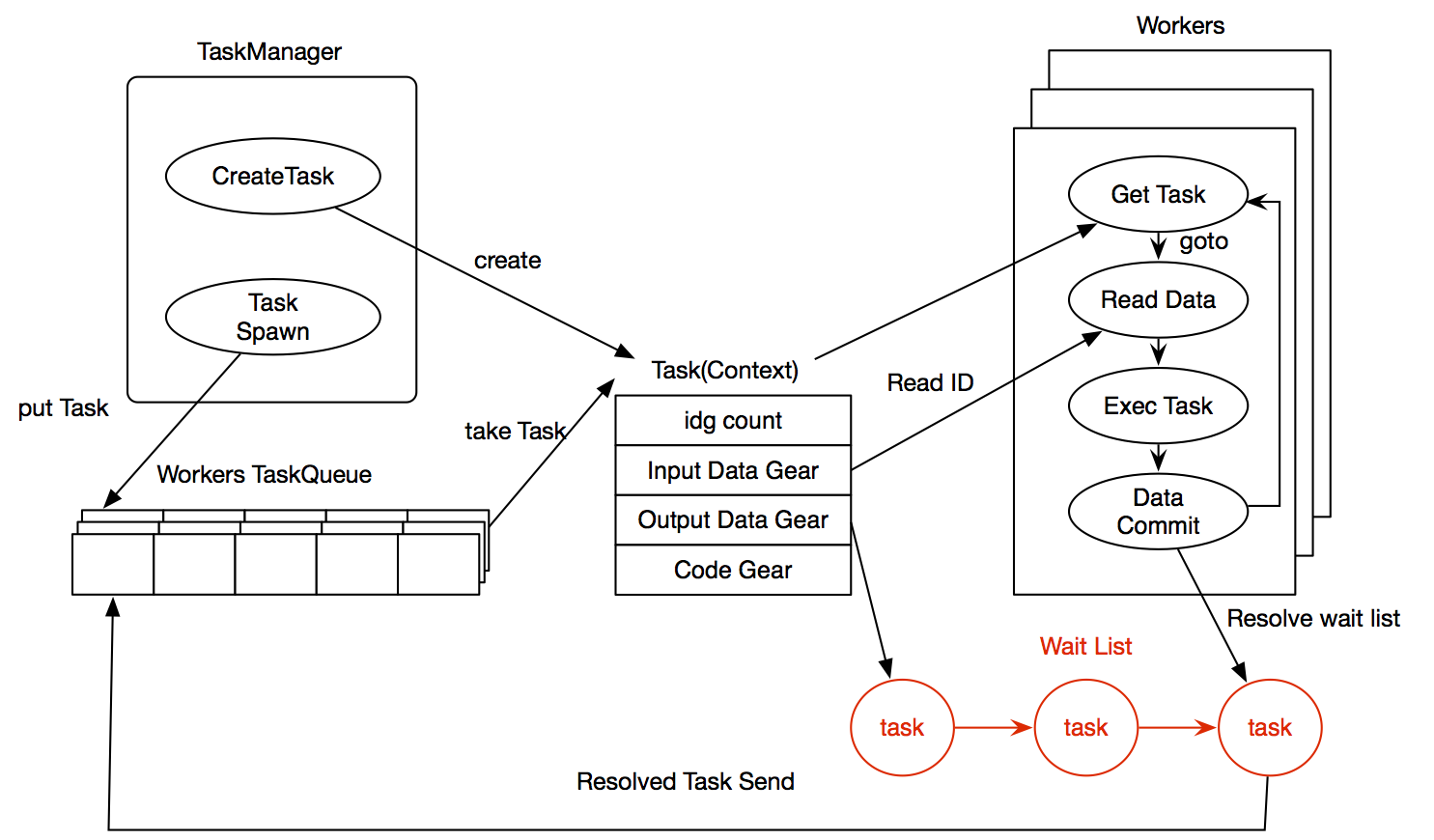
Gears OS の構造
- Gears OS は以下の要素で構成されている
- Context
- TaskQueue
- TaskManager
- Worker
Context
- 1つのスレッド内で使われる Interface の Code Gear と Data Gear は Meta Data Gear に格納される。
- この Meta Data Gear を Context と呼ぶ。
- Context を複製して複数の CPU に割り当てることにより並列実行が可能になる。
- ノーマルレベルでは見る事ができない。
- Context は Task でもある。
- Task は実行する Code Gear と Data Gear を全て持っている。
TaskManager
- Task を実行する Worker の生成
- Worker の管理
- Task の送信
Worker
- TaskQueue から Task である Context を取得
- Task の Code Gear を実行
- Output Data Gear への書き出し
1つの Code Gear の実行は他の Code Gear に割り込まれない
- 共有された Data Gear があった時に、それに対する変更はただ1つの Code Gear だけが許される
- 読み込みは複数であってもいい
- Agda 側で、並列実行を Code Gear の順次実行としてシミュレーションするため
- このような実行になるように Gears OS の実装を行う
par goto
- Context(Task) の複製には par goto を用いる。
- 他に、入力の同期、タスクスケジューラへの Context の登録が行われる。
- 複数実行した時に、共有 Data Gear に書き込みを成功したかを確認(commit)するために __exit を使用する。
- par goto で生成された Task は __exit に継続することで終了する
- GearsOS の Task は Output Data Gear を生成した時点で終了する
- そのため、par goto では直接 __exit に継続せず、Output Data Gear への書き出し処理に継続される。
__code code1(Integer *integer1, Integer * integer2, Integer *output) {
par goto add(integer1, integer2, output, __exit);
goto code2();
}
__code code1(struct Context *context, Integer *integer1, Integer *integer2, Integer *output) {
// create context
context->task = NEW(struct Context);
initContext(context->task);
// set task parameter
context->task->next = C_add;
context->task->idgCount = 2;
context->task->idg = context->task->dataNum;
context->task->maxIdg = context->task->idg + 2;
context->task->odg = context->task->maxIdg;
context->task->maxOdg = context->task->odg + 1;
...
// set TaskManager->spawns parameter
Gearef(context, TaskManager)->taskList = context->taskList;
Gearef(context, TaskManager)->next1 = C_code2;
goto parGotoMeta(context, C_code2);
}
スライドの流れ
- Interface
- 並列API
- CbC
- Gears OS における並列実行
-
比較
- 今後の課題
Gears OS の評価(目的)
- 並列構文とそれを実現する Meta Compitation が十分に揃っているかを確認したい
- 並列処理の台数効果を確認する
- 既存の並列言語と比較して不要なオーバーヘッドがあるか調べたい
Gears OS の評価(環境)
- CPU、GPU環境で Gears OS の測定を行う。
- 使用した環境は次のようになる。
- CPU 環境
- Model : Dell PowerEdgeR630
- Memory : 768GB
- CPU : 2 × 18-Core Intel Xeon 2.30GHz
- GPU 環境
- GPU : GeForce GTX 1070
- Cores : 1920
- ClockSpeed : 1683MHZ
- Memory Size : 8GB GDDR5
Twice
- 評価には与えられた整数配列の全ての要素を2倍にする例題である Twice を使う。
- Twice では 通信時間を考慮しなければ、CPU より コア数の多い GPU が有利となる。
- 要素数2^27のデータに対する Twice の実行結果を示す。
- CPU では2^27のデータを64個のデータに分割した。
- kernel only は 通信速度を除いた速度である。
| Processor |
Time(ms) |
| 1 CPU |
1181.215 |
| 2 CPUs |
627.914 |
| 4 CPUs |
324.059 |
| 8 CPUs |
159.932 |
| 16 CPUs |
85.518 |
| 32 CPUs |
43.496 |
| GPU |
127.018 |
| GPU(kernel only) |
6.018 |
評価の考察
- コア数が上がるごとに、処理速度が上がっている。
- GPUでの実行は 32CPU に比べて約7.2倍の速度向上が見られた。
- 通信速度を含めると 16CPU より遅い。
| Processor |
Time(ms) |
| 1 CPU |
1181.215 |
| 2 CPUs |
627.914 |
| 4 CPUs |
324.059 |
| 8 CPUs |
159.932 |
| 16 CPUs |
85.518 |
| 32 CPUs |
43.496 |
| GPU |
127.018 |
| GPU(kernel only) |
6.018 |
Go 言語との比較
- Go 言語でも Twice を用いた検証を行い、Gears OS との速度比較を行なった。
- 1CPU と 32CPU では約4.33倍の速度向上が見られた。
- CPU数による速度向上は、Gears OS の方が上だが、処理速度では Go言語の方が速い結果となった。
スライドの流れ
- Interface
- 並列API
- CbC
- Gears OS における並列実行
- 比較
-
今後の課題
スライドの流れ
- CbC
- Gears OS における並列実行
- 比較
-
今後の課題
今後の課題
- Go 言語との比較から 1CPU での動作が遅いことがわかった。
- par goto 文を使用することで、Contextを生成し、並列処理を行う。
- しかし、Context はメモリ空間の確保や使用する全ての Code Gear Data Gear の設定をする必要があり、生成に時間がかかってしまう事が原因。
- 処理が軽い場合は Context を生成しないようなチューニングが必要である。
Perlスクリプトによる変換
__code code1(struct Context *context, Integer *integer1, Integer *integer2, Integer *output) {
// create context
context->task = NEW(struct Context);
initContext(context->task);
// set task parameter
context->task->next = C_add;
context->task->idgCount = 2;
context->task->idg = context->task->dataNum;
context->task->maxIdg = context->task->idg + 2;
context->task->odg = context->task->maxIdg;
context->task->maxOdg = context->task->odg + 1;
// create Data Gear Queue
GET_META(integer1)->wait = createSynchronizedQueue(context);
GET_META(integer2)->wait = createSynchronizedQueue(context);
GET_META(integer3)->wait = createSynchronizedQueue(context);
// set Input Data Gear
context->task->data[context->task->idg+0] = (union Data*)integer1;
context->task->data[context->task->idg+1] = (union Data*)integer2;
// set Output Data Gear
context->task->data[context->task->odg+0] = (union Data*)integer3;
// add taskList Element
struct Element* element;
element = &ALLOCATE(context, Element)->Element;
element->data = (union Data*)context->task;
element->next = context->taskList;
context->taskList = element;
// set TaskManager->spawns parameter
Gearef(context, TaskManager)->taskList = context->taskList;
Gearef(context, TaskManager)->next1 = C_code2;
goto meta(context, C_code2);
}